Working Off Main Isn't Sacrilege
I recently came across this post and I could have cried (for joy). Stacked diffs are finally getting native support on GitHub, something I’ve been waiting to enter the mainstream conversation for years.
Why does this matter? Reviewing giant PRs is incredibly painful, and diff stacking eases that burden enormously. I’ve been doing it for a few years now and couldn’t go back to a standard trunk-based workflow if I tried. Here’s how I got there, and what I eventually built along the way.
Before I Knew What I Was Doing
Before git, I was doing what I imagine most people did: versioning by folder.
data_v1, data_v2, data_v2_final. Painful… but it was all I knew.
Then university introduced me to git as part of my Software Engineering degree, and it was an immediate revelation. Branches were seamless: you could spin one up, make changes, roll them back, and never lose track of what you’d done elsewhere. It felt like the chaos of folder versioning had been replaced with something that actually made sense.
Starting my career, the standard workflow was trunk-based: short-lived branches off main, build the feature, open a PR, get it reviewed, merge back into trunk. Neat enough. Until it wasn’t. The problem crept up whenever I’d finish a piece of work and need to pick up the next thing that built on top of it. The first feature is sitting in review, not yet merged, and I’m blocked. Waiting is dead time. Working on a separate branch means I’m about to make my life very difficult the moment both need to land. The trunk-based model had hit its ceiling.
When Branches Stop Scaling
The trunk-based model breaks down the moment your work has dependencies. You finish a piece of work, open the PR, and immediately need to start the next thing, which builds directly on top of what you just submitted. Your options aren’t great:
- wait for the review to land (dead time),
- start a new branch off main and duplicate the setup (painful to reconcile later), or
- stack a branch on top of the unmerged one and open a PR against it (messy diffs, and if the base branch changes, you’re in for a bad time).
None of these feel right because none of them are right. The workflow just isn’t designed for dependent work in flight.
A colleague at Juicebox introduced me to Graphite, which handles exactly this: stacked branches, managed for you. And honestly, the stacking itself was great. But Graphite came with a lot I didn’t need. The product is essentially a GitHub replacement UI on top of the CLI, and I found it got in the way more often than it helped. I only ever cared about the CLI. There’s also a harder problem with any team tool: you need the whole team onboard and paying for it before the benefits become obvious, which makes it a difficult sell. The positives don’t materialise until everyone’s already using it, a classic chicken-and-egg that makes adoption an uphill battle.
EDIT: I’ve noticed that it is now getting integration into Cursor, so there could be some merits to try it again!
Discovering Git Patch Stack
Looking for Graphite alternatives, I stumbled onto Drew DePonte’s
blog and his tool, git patch
stack. What he was describing was something I’d never
seriously considered: working directly off main. To a developer raised on
trunk-based branching, that sounds like sacrilege. It isn’t. I practice it like
it’s my faith now.
The mental shift git patch stack demands is this: stop thinking about work as
branches, and start thinking about it as a series of small, atomic commits. Each
commit represents one self-contained piece of work. Your whole stack of
in-progress changes lives on a single branch (main, or whatever your base is)
and tooling handles creating the isolated review branches for each commit when
you’re ready to open a PR.
In practice the workflow looks like this:
# Traditional branch stacking
main
└── feature/auth <- PR #1
└── feature/logging <- PR #2 (based on feature/auth, messy diffs, fragile)
# Patch stack
main
├── commit: Add auth <- tooling creates review branch -> PR #1
└── commit: Add logging <- tooling creates review branch -> PR #2
You never switch branches. You just keep committing, keep each change focused and atomic, and let the tooling figure out the review branches. The caveats are real. Sometimes a commit genuinely depends on the one before it, but the discipline of keeping commits small means those dependencies are explicit and manageable rather than a tangled mess of branch history.
What git patch stack Was Missing (For Me)
Git patch stack is excellent at the core workflow, but it left me wanting more
control. Branch naming in particular bothered me. I wanted auto-generated review
branch names derived from the commit message, with configurable prefixes (e.g.
username/feat/add-auth) and control over formatting like separators and length
limits. Small things individually, but the kind of friction that adds up when
you’re running the same workflow dozens of times a week.
That was enough to make me build my own tool rather than work around it. And once I started, the backlog of things I wanted grew: auto rebase resolution on merge, stack reordering, better visibility into which commits are already under review. Git patch stack planted the seed; I just wanted to grow it in a direction that fit how I actually work.
Building Glu
Glu is a CLI tool that brings the patch stack workflow with the configurability and tracking I was missing. The feature I’m most proud of is the Glu ID system, and it solves a problem that’s easy to overlook until it bites you.
Git identifies commits by their SHA hash. When you rebase (which in a patch stack workflow you do constantly), those hashes change. That means any tracking data tied to a hash silently breaks. Glu sidesteps this by embedding a stable, unique ID directly into the commit message as a git trailer:
feat: add auth middleware
Glu-ID: glu_abc123_def456
The ID lives in the commit itself, so it survives rebases, cherry-picks, and anything else that would change the hash. Glu uses these IDs to maintain a local graph of which commits are in which review branches, giving you full visibility into the state of your stack at any point.
The basic workflow looks like this:
# Your stack of commits on main
git commit -m "feat: add auth middleware"
git commit -m "feat: add request logging"
git commit -m "fix: handle auth edge case"
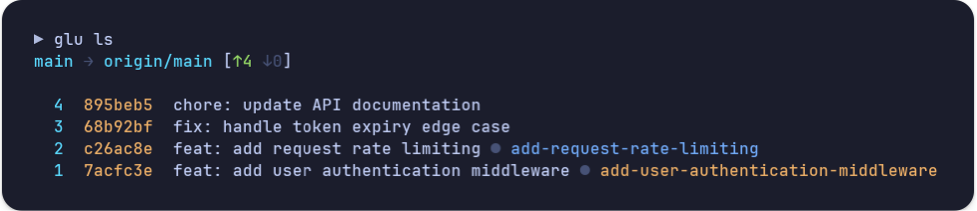
# See what's unpushed, with indices
glu ls
# Open PRs for specific commits (no branch switching required)
glu rr 1 # auth middleware -> its own PR
glu rr 2-3 # logging + fix -> one PR
No branch switching, no manual cherry-picking, no tracking that falls apart after a rebase. The repo is at github.com/LachlanMcCulloch/glu. Feedback and contributions welcome.
Where This Is All Going
The GitHub announcement isn’t the death of tools like Glu or git diff stack. It’s the opposite. Native UI support for stacked diffs means the workflow is finally getting the mainstream recognition it deserves, but GitHub’s integration only handles one half of the problem: the PR side. It doesn’t manage your stack locally. It doesn’t know which commits are in review, track them through a rebase, or automate the branch creation. That’s still on you, and that’s exactly the gap that local tooling fills. If anything, more developers discovering stacked diffs through GitHub means more developers who’ll want a proper local workflow to go with it.
For Glu, I’ve got a clear list of what comes next: automatic rebase resolution when a stack base merges, and stack reordering when the order of your commits needs to change mid-flight. Both are things that git patch stack doesn’t handle and that come up regularly in practice. If you’re trying out the patch stack workflow and find Glu useful, or have opinions on what’s missing, I’d love to hear it.
Subscribe for updates
Want more like this? Get new posts in your inbox. No spam, ever.